Input video
Edited Video








Despite significant advancements in video generation, inserting a given object into videos remains a challenging task. The difficulty lies in preserving the appearance details of the reference object and accurately modeling coherent motion at the same time. In this paper, we propose VideoAnydoor, a zero-shot video object insertion framework with high-fidelity detail preservation and precise motion control. Starting from a text-to-video model, we utilize an ID extractor to inject the global identity and leverage a box sequence to control the overall motion. To preserve the detailed appearance and meanwhile support fine-grained motion control, we design a pixel warper. It takes the reference image with arbitrary key-points and the corresponding keypoint trajectories as inputs. It warps the pixel details according to the trajectories and fuses the warped features with the diffusion U-Net, thus improving detail preservation and supporting users in manipulating the motion trajectories. In addition, we propose a training strategy involving both videos and static images with a weighted loss to enhance insertion quality. VideoAnydoor demonstrates significant superiority over existing methods and naturally supports various downstream applications (e.g., video face swapping, video virtual try-on, multi-region editing) without task-specific fine-tuning.
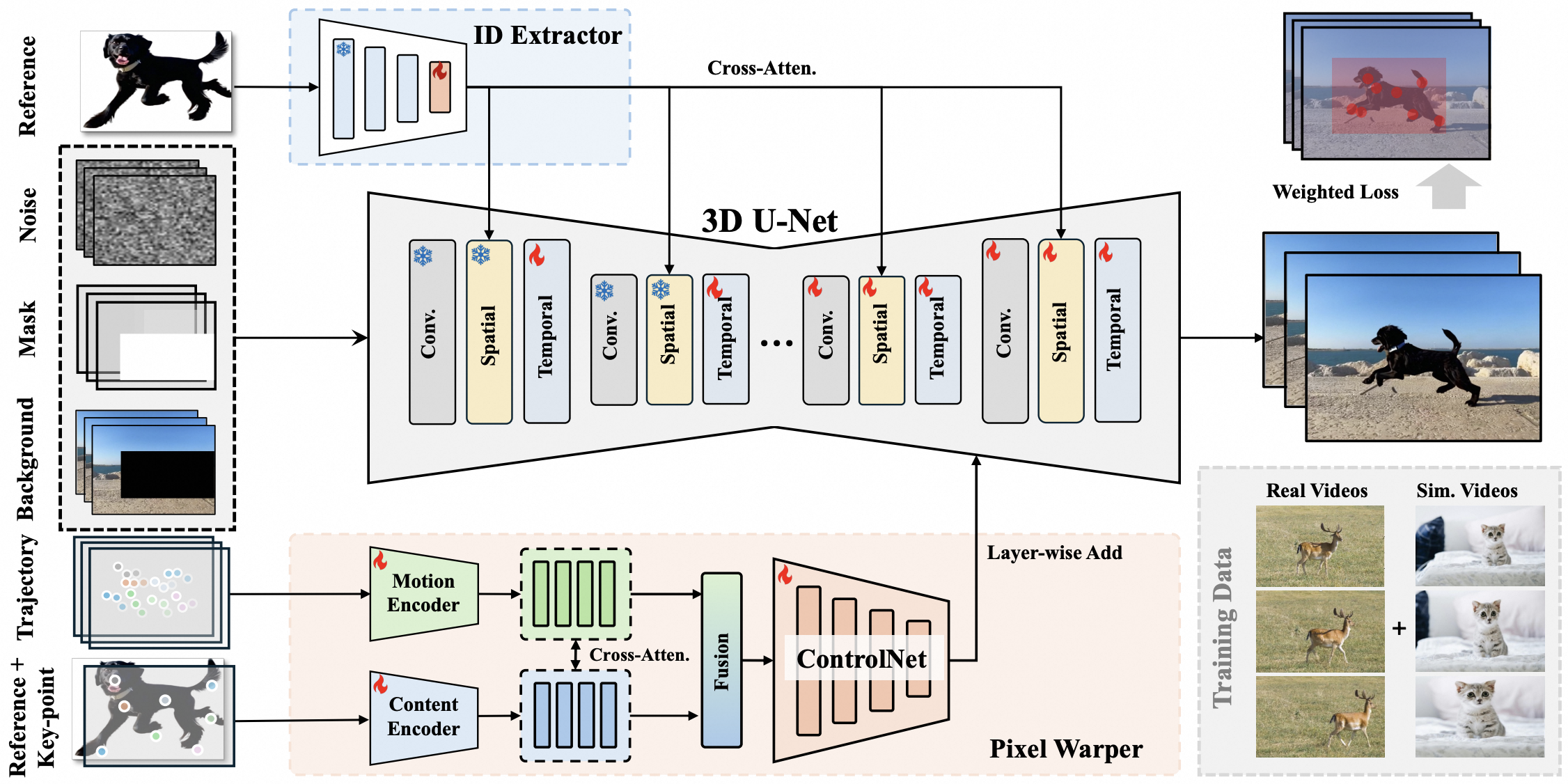
In this paper, we propose VideoAnydoor, a zero-shot video object insertion framework with high-fidelity detail preservation and precise motion control. First, we input the concatenation of the original video, object masks, and masked video into the 3D U-Net. Meanwhile, the background-removed reference image is fed into the ID extractor, and the obtained features are injected into the 3D U-Net. In our pixel warper, the reference image marked with key points and the trajectories are utilized as inputs for the content and motion encoders. Then, the extracted embeddings are input into cross-attentions for further fusion. The fused results serve as the input of a ControlNet, which extracts multi-scale features for fine-grained injection of motion and identity. The framework is trained with weighted losses. We use a blend of real videos and image-simulated videos for training to compensate for the data scarcity.
@misc{tu2025videoanydoorhighfidelityvideoobject,
title={VideoAnydoor: High-fidelity Video Object Insertion with Precise Motion Control},
author={Yuanpeng Tu and Hao Luo and Xi Chen and Sihui Ji and Xiang Bai and Hengshuang Zhao},
year={2025},
journal={arXiv preprint arXiv:2501.01427},
}

